
Checkpoint-One
Our first 72B checkpoint is here and it is the most powerful decentralized pretrained model

Covenant72B Progress Report: Our First Large-Scale Globally Distributed 72B Run
We’re excited to share an update on Covenant72B, our first large-scale 72B LLM training run. This marks a significant milestone—not just for our team, but for the broader vision of decentralized AI development

.
What is Covenant AI?
Covenant AI is building the foundation for large-scale, decentralized AI training. We’re developing three interconnected platforms on the Bittensor blockchain:
Templar - Decentralized pre-training
Basilica - Decentralized compute
Grail - Decentralized RL post-training
Templar, our pre-training platform, enables permissionless, decentralized pre-training of large language models. Instead of requiring a single datacenter, we coordinate participants around the world using novel algorithms that address the fundamental challenges of decentralized pre-training—particularly the communication bottleneck. Templar runs live, 24/7, with the goal of producing models competitive with centralized labs.
So far, we’ve published two key papers that underpin this work:
Gauntlet — a blockchain-compatible reward mechanism for allocating incentives and encouraging honest and efficient participation.
SparseLoCo — a new state-of-the-art communication-efficient optimizer.
You can check out more details of these publications here, and they will be both presented at this year’s NeurIPS Optimization Workshop.
In addition, we’ve pioneered a unique approach to cross-participant communication by leveraging object storage. Combined with SparseLoCo, this enables participants to exchange highly compressed pseudo-gradients in a way that is both efficient and auditable. With this setup, peers can join permissionlessly by creating an object storage bucket and posting their read key and bucket location on-chain. The mechanism ensures transparent, time-stamped records of contributions and allows rewards to be allocated based on verifiable behavior.
Together, these methods form the backbone of our pre-training runs today.
What is Covenant72B?
Until now, we’ve focused on stabilizing the Templar system by running model sizes 1B-8B (including TEMPLAR I, our first successful fully permissionless run) with permissionless participants on the Bittensor blockchain. That work has hardened our infrastructure, reward mechanism, and inspired our algorithms.
Covenant72B represents our first attempt at scale. We’re training a 72B-parameter model on at least 1.2 trillion tokens—a full demonstration of permissionless decentralized pre-training at a size that matters.
Launched on September 12th, the run is progressing well. The first checkpoint (Checkpoint One) is now available on Hugging Face, with more checkpoints to follow as training continues.
Anyone in the world can participate freely, with no approval process required (https://www.tplr.ai/). The system is battle-tested to ensure useful contributions, though participants currently need at least 8xB200 GPUs (or equivalent) to be competitive.
Technical Specs
Model size: 72B
Architecture: LLaMA-style
Target token budget: 1.2T
Compute participants: 20+
Minimal compute requirements per participant: 8xB200 or equivalent
Dataset: DCLM-baseline (for the first 1.2T tokens), and potential custom data mixtures towards the end of training
Optimizer: SparseLoco
We designed this run to facilitate comparison with large open-source models trained in centralized datacenters.
Current Progress
Judging progress early in a trillion-token run is tricky. We’re monitoring the health of the system through multiple signals: loss and downstream metrics (fortunately few spikes), cross-run comparisons, and reference checkpoints. Our primary baseline is K2 from MBZUAI (llm360.ai)—an open-source model at a similar scale with public checkpoints. This lets us make direct comparisons to a centralized run at similar time points in training.
In the tables below, we compare our first checkpoint against two other decentralized pre-training runs (conducted with white listed participants unlike our permissionless runs) and several K2 checkpoints at similar training stages.
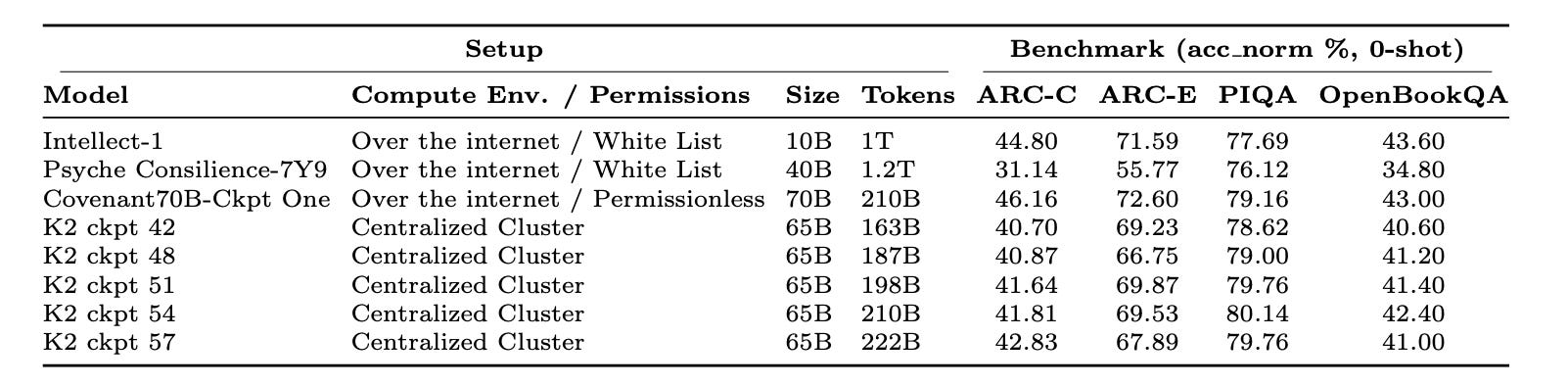
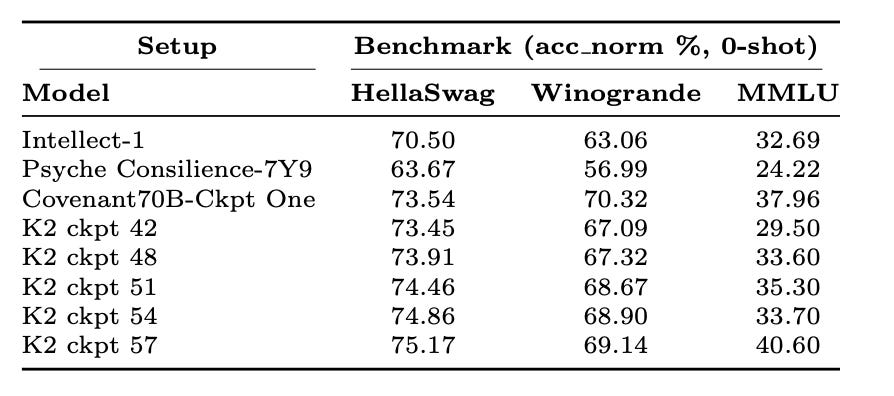
The results are encouraging. Checkpoint One already outperforms existing completed large-scale decentralized runs across all metrics, making it the most powerful collaboratively pre-trained model to date, training entirely over the open internet—and crucially, in a fully permissionless environment.
When compared to K2 checkpoints, our model is on target. We show better performance on ARC-C and ARC-E, while tracking slightly behind on HellaSwag and MMLU. This suggests our run is matching the quality of centralized training—a key validation point, given that many decentralized pre-training efforts can struggle to achieve parity with centralized baselines.
A note on token estimation: Templar’s system doesn’t allow us to measure exact token counts with perfect precision—miners communicate only pseudo-gradients and can optimize their throughput independently through code improvements or better hardware. We’ve calibrated the system for our optimized base miner code, and we typically detect when miners improve their throughput. In response, we decrease their processing time windows, which both improves system efficiency and makes token estimates more reliable. Our estimates combine the number of active miners, target batch size on the recommended hardware, inner steps, and sequence length. We also apply a correction factor to account for gradient upload failures.
Communication efficiency: Our system currently maintains only 6% overhead for communication between peers—highly competitive for training over the internet even at smaller scales.
As with any ambitious technical undertaking, this run has surfaced several challenges:
Validator stability: In Templar, a validator is a participant that stakes tokens on the blockchain and monitors the quality of contributions, assigning rewards accordingly. The largest-stake validator (or the most trustworthy one) is also responsible for maintaining checkpoints that peers use to synchronize when joining late or resynchronizing when they fall out of sync. In this run, due to the scale of the model, we’ve experienced validator instability (e.g. OOM issues etc) which can downstream cause participant desynchronization. We’ve implemented improvements to handle edge cases and ensure continuous operation.
Peer synchronization: Miners occasionally desynchronize or submit data outside optimal timing windows. We made revisions to the reward mechanism to minimize this issue.
What’s Next
This is just the beginning. We are carefully optimistic about the run at this early stage and we’ll continue releasing checkpoints, and sharing what we learn about decentralized training at the largest scales. We expect to make this run and our future training runs faster over time through engineering efforts and R&D. Our engineering team believes there is significant speed up that can be obtained by reducing known bottlenecks. Furthermore, our team is working on significant R&D efforts to improve the algorithm to scale up the number of participants and to reduce the compute requirements of individual participants.
Covenant is also working on two efforts to directly support the full training pipeline: a decentralized compute rental platform (Basilica) which is being designed with our training runs in mind and a decentralized post-training platform which will incentivize participants to highly optimize the generation of rollouts for RL post-training.
Stay tuned—and if you want to follow along, check out the model on Hugging Face and the latest updates from Covenant AI.
We are also hiring experienced ML researchers and engineers with LLM training experience. Reach out at contact@tplr.ai
Note about organization name: What started as Templar has expanded into Covenant AI, a community developing three interconnected platforms on the Bittensor network: Templar (decentralized pre-training), Basilica (decentralized compute), and Grail (decentralized post-training).